1: FirstOrDefault and similar
We all know this LINQ method that we almost all use everyday -
FirstOrDefault, it works great, is incredibly handy, but it has one small annoyance.
Let's talk about this $hot_topic lately - error handling. So unlike
First,
FirstOrDefault doesn't throw an Exception in order to communicate that something went wrong, namely - nothing was found.
FirstOrDefault as the name says returns default value in such a case, which in practice almost always results in code which some kind of NULL check
| var list = new List<User> { new User("Tom"), new User("John"), new User("Andrew")}; |
| var first = list.FirstOrDefault(x => x.FirstName == "Tony"); |
| Console.WriteLine(first is null); |
Basically null is being treated as a
"not found value" / "error value".
It's not perfect, but it works really well in practice, I think I've never been in scenerio like this below that would broke this assumption
| var list = new List<User> { null, new User("Tom"), new User("John"), new User("Andrew")}; |
| var first = list.FirstOrDefault(); |
The problem here is that things are kinda tricky - the
null is not
"not found" value, but an actual value from the collection.
I do agree that this is very theoretical scenerio and probably we will never have to deal with something like this, but it adds some kind of unceratnity.
The things are getting worse when we start dealing with value types, and this is actually the scenerio that I tend to run into from time to time
| var list = new List<int> { 1, 2, 3 }; |
| var first = list.FirstOrDefault(x => x > 3); |
| Console.WriteLine(first); |
Sure, there's no "WTF" in this code, the behaviour is known to "everybody", the work-arounds are known too, but it sucks.
Is 0 the legit value? or not? it could be, but who knows, so we end up with something like this
| var list = new List<int> { 1, 2, 3 }; |
| var first = list.Select(x => (int?)x).FirstOrDefault(x => x > 3); |
| Console.WriteLine(first is null); |
or use one interesting overload of
FirstOrDefault like this, or use other e.g
Cast based approach, but it's just implementation detail, the concept itself is the same.
| var list = new List<int> { 1, 2, 3 }; |
| var first = list.FirstOrDefault(x => x > 3, 17); |
| Console.WriteLine(first); |
but the problem with this approach is that it may be hard or even impossible to pick some value that will behave as an error value.
I believe that having
Result (
naive example here, not prod ready) would help when it comes to dealing with those scenerios
| public struct Result<T> |
| { |
| public bool Success { get; private set; } |
| |
| public T Data { get; private set; } = default(T); |
| |
| public static Result<T> Ok(T data) |
| { |
| return new Result<T> { Success = true, Data = data }; |
| } |
| |
| public static Result<T> Fail() |
| { |
| return new Result<T> { Success = false, Data = default(T) }; |
| } |
| } |
| |
| public static class Ext |
| { |
| public static Result<T> FirstResult<T>(this IEnumerable<T> elements, Func<T, bool> func) |
| { |
| foreach (var element in elements) |
| if (func.Invoke(element)) |
| return Result<T>.Ok(element); |
| |
| return Result<T>.Fail(); |
| } |
| } |
Usage:
| var list = new List<int> { 1, 2, 3 }; |
| var first = list.FirstResult(x => x > 3); |
| if (first.Success) |
| { |
| Console.WriteLine(first.Data); |
| } |
| else |
| { |
| Console.WriteLine("Not found"); |
| } |
Case with null value in collection:
| var list = new List<User> {null, new User("Tom"), new User("John"), new User("Andrew")}; |
| var first = list.FirstResult(); |
| |
| if (first.Success) |
| { |
| Console.WriteLine($"Found: {first.Data}"); |
| } |
Of course it required some tweaks to our extension
| public static class Ext |
| { |
| public static Result<T> FirstResult<T>(this IEnumerable<T> elements, Func<T, bool> func = null) |
| { |
| if (func is null) |
| { |
| if (elements.Any()) |
| return Result<T>.Ok(elements.ElementAt(0)); |
| else |
| return Result<T>.Fail(); |
| } |
| |
| foreach (var element in elements) |
| if (func.Invoke(element)) |
| return Result<T>.Ok(element); |
| |
| return Result<T>.Fail(); |
| } |
| } |
I think we don't have something like FirstResult because there's no built-in Result-like type yet, but I hope once we receive one, then we'll revisit "old" APIs and support more precise ways of handling errors.
2: "?" may feel inconsistent
I really thought
T? is going to be nullable, but it was just
T.
Basically as far as I know - in C# we cannot express elegantly the concept of nullable generic type that works for both - value and ref types at once,
we need to have two different methods that put constrains "where T : struct/class" or using some wrapper class/struct.
Rookie mistake, I guess.
| public static void Foo(int? a) |
| { |
| Console.WriteLine(a is null); |
| Console.WriteLine($"'{a}'"); |
| } |
| |
| public static void Bar<T>(T? a) |
| { |
| Console.WriteLine(a is null); |
| Console.WriteLine($"'{a}'"); |
| } |
| |
| public static void Quux<T>(T? a) where T : struct |
| { |
| Console.WriteLine(a is null); |
| Console.WriteLine($"'{a}'"); |
| } |
| |
| public static void Quux2<T>(T? a) where T : class |
| { |
| Console.WriteLine(a is null); |
| Console.WriteLine($"'{a}'"); |
| } |
| |
| public static void Main(string[] args) |
| { |
| Foo(default); |
| Console.WriteLine("_____"); |
| Bar<int>(default); |
| Console.WriteLine("_____"); |
| Bar<int?>(default); |
| Console.WriteLine("_____"); |
| Quux<int>(default); |
| Console.WriteLine("_____"); |
| Quux2<Program>(default); |
| } |
3: What does it even mean?
This one I found accidentally I think, I believe Visual Studio or Roslynator offered me this refactoring / hint.
So I had hierarchy like this:
| public abstract class Node |
| { |
| public override string ToString() |
| { |
| return base.ToString(); |
| } |
| } |
| |
| public class SomeNode : Node |
| { |
| public override string ToString() |
| { |
| return "It's SomeNode"; |
| } |
| } |
but I wanted to force classes deriving from
Node to write their own
ToString and accidentally met that
abstract override, that worked as expected despite feeling pretty weird.
| public abstract class Node |
| { |
| public abstract override string ToString(); |
| } |
| |
| public class SomeNode : Node |
| { |
| public override string ToString() |
| { |
| return "It's SomeNode"; |
| } |
| } |
| |
| public class SomeNode2 : Node |
| { |
| |
| } |
Later I found that even Eric Lippert has an article about this and even very similar usecase
Strange but legal
“Can a property or method really be marked as both abstract and override?” one of my coworkers just asked me. My initial gut response was “of course not!” but as it turns out, the Roslyn codebase itself has a property getter marked as both abstract and override. (Which is why they were asking in the first place.)
Now I noticed that there's also

4: Explaining to student: "something like this works in 'old C#', but not in the 'new'
Nothing's weird about this code, everything's fine, pretty standard stuff.
| void Foo(string a) |
| { |
| Console.WriteLine(a); |
| } |
| |
| void Foo(int a) |
| { |
| Console.WriteLine(a); |
| } |
Except when you use it in a top-level statement program.
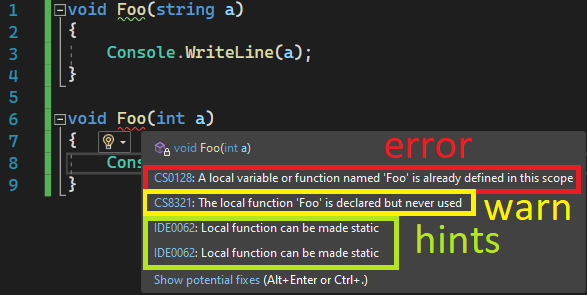
I wouldn't want to be challenged with question like "why we can use it there (whole class), but we can't use it here (top-level statements)?"