- <50ppl
- Automation tooling is basically non-existent
- There's not small amount of customers and majority of them has a few products
- Almost all of those products are tightly coupled to external software, by "tightly coupled" I mean that you have not only to compile those products with this external software but also play with its rules (e.g versioning)
- Release cycle is around 2-4 weeks where new version of external software is published and you gotta recompile all of your products and deploy them.
- Almost all of products aren't server side, you actually gotta use customer's maintenance window and deploy it on their hardware. Other team (non-dev) was responsible for deploy and we wanted to make them independent from dev team. For example devs work 8-16, the "deploy team" could work like e.g 8:30-16 + 30min around midnight
- Products weren't written with automation in mind
- All of that was happening inside .NET world
1: Customizability
I've heard about all those CI/CD and fancy tools for automation, but besides automated tests on GitHub Actions I never actually used them and since I came with an initiative to automate this stuff, then I had to decide. Since I felt like our process is incredibly complex mess, then I felt like we have to come with our own $solution, right? Because what could be difficult here? you just compile project and copy output to some location, right? So, quoting some other blog: Reality has a surprising amount of detail(s) Let's get back to the reality a) We're within .NET world, mostly old .NET Framework, around .NET 4, 4.5 versions. I personally started doing .NET for money when .NET Core was released and maybe I just significantly lack of knowledge, or old .NET was really not-automation-friendly. Everything coupled to Visual Studio, .NET compiler (or actually wrapper / build system) hidden somewhere 10 meters deep inside VS' installation folder, not accessible from CLI unless you manually added it to path or probably used some "developer console" which does not make sense to me at all. Then you have nuget packages with could be really problematic when you broke something e.g via moving project and the solution was to performUpdate-Package -reinstall inside Visual Studio's nuget package manager.
Warning: Probably this last sentence is full of bullshit and you could do that better/easier/faster/yadayada, but the thing is that in newer .NET - since Core this stuff works times better, out of the box. Nugets are more stable.
Since Core - .NET doesn't feel like terminal/cli was some weird concept and actually started treating it as first class citizen.
b)
Let's move to the next thing: the source code must be stored somewhere, right? zip files!
just kidding, no zip files, but not git either, you can probably guess - it's Microsoft's TFVC.
Two annoying things when working with this tool is that you have to perform "checkout" on file that you want to edit and that when you perform "load changes" (fast operation) then im some specific scenerios it may not load everything and you have to perform "full scan" which took e.g 15 min
c)
When you compile project let's say "compiler.exe myproject" then what do you expect to happen? project compiles, generates binary or throws errors and the process exits, right?
Not that easy. MSBuild doesn't exit in order to be faster. It gave me a lot of problems when I've been thinking "Why the hell my program is getting randomly stuck after reading output from compiler"
Quote from StackOverflow:
Briefly: MSBuild tries to do lots of things to be fast, especially with parallel builds. It will spawn lots of "nodes" - individual msbuild.exe processes that can compile projects, and since processes take a little time to spin up, after the build is done, these processes hang around (by default, for 15 minutes, I think), so that if you happen to build again soon, these nodes can be "reused" and save the process setup cost. But you can disable that behavior by turning off nodeReuse with the aforementioned command-line option.
Due to the constrains, more or less known at the beginning of the project I decided that we need to have insane customizability. So, how to start modeling building system like this? how it'll know where project is stored? I instantly thought about classes! oop! that'd be mistake, fortunely more experienced dev gave me incredibly good advice - it should be kinda data driven. It means that program performs some kind of "discovery" - scans whole repo (after sync) and searches for "register" (json) files which contain basic information about product - path to project file, project name, customer, some configuration (configuration was especially important lesson, below).
// register.file { "ProjectName": "App1", "CustomerName": "Customer1" "PathToSourceCode": "../file.sln", ... }This way you can add new project without touching either source code or some database. Nice, now we know almost everything we need, we know where product's source code is located. Now we want to have that customizability, every project should have its own script that builds and copies it. I started adding our "register.file" (json) and "compile.script", "copy.script" to every project. During that process I had to perform some small modifications to existing projects in order to make them more automation friendly and after some time I realized that I have bug in my "copy.script", so what I had to do now? I had to edit let's say 100 "copy.script" files. I did that, but the next time I had some time to work on this project I realized that we didn't need that significant customizability after all! Majority of source codes could be grouped into e.g 2 groups where first one has 99% of the projects and 2nd one the rest. So, the idea was: instead of having hundreds of script files, let's assign every code project to some of the group via our "register.file" (json) and by default use scripts from some "DefaultScript" directory, so this way we could reduce amount of script files to maintain from e.g 100 to 4.
// register.file { "ProjectName": "App1", "CustomerName": "Customer1" "PathToSourceCode": "../file.sln", "Group": "A" } { "ProjectName": "App2", "CustomerName": "Customer2" "PathToSourceCode": "../file.sln", "Group": "A" "OverrideCopyScript": "my_custom.script" }Additional lesson from this thing is something I call "sane config"/"sane defaults", for example when 99% of configuration ("register.file") files used the same value for one thing, then why display it at all in config file? By using default values when the value was not provided I could cut huge chunk of configuration in order to make it more readable, yet still configurable (config file format was documented). The even more AI™ example is that the tool itself needs to know where MSBuild.exe is, but as I said it's somewhere deep inside VS installation folder and it wasn't that clear where it was
// tool_config.file { "MSBuild": "C:\\Program Files\\Microsoft Visual Studio\\{2022|2019|2017|2015...}\\{Enterprise|Professional}...........", ... }So the developer that wanted to mess with this had to configure this path, but if you think about it, then it wasn't necessary That thing could be left empty
// tool_config.file { "MSBuild": "", ... }and when it's empty, the tool could perform search and try to find it and if it managed to find it, then override the config, so something like "first-run" configuration.
2: Splitting UI and Backend
MVP worked fine, but it was still CLI, meanwhile it had to be used by people who prefer fancy GUIs, clickability, tables and stuff, and there's nothing wrong with that. Existing CLI tool received some small modifications like checking the database whether some "task" to perform is there and GUI was written, the whole architecture looks like this: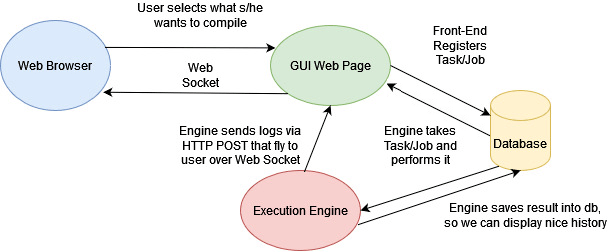 While you could easily perform heavy tasks inside ASP .NET Core's Controller / Service / MediatR Handler, then I felt like having those things separated into frontend/backend apps is good way of doing this.
I don't know, but for some reason it reminds me Linux's Wayland's client/server.
While you could easily perform heavy tasks inside ASP .NET Core's Controller / Service / MediatR Handler, then I felt like having those things separated into frontend/backend apps is good way of doing this.
I don't know, but for some reason it reminds me Linux's Wayland's client/server.
3: Maintenance, also users may not even try
When compilation error occured, then this tool basically copied compiler's output to user (could be developer too) You know, very similar error that he'd receive when s/he tried to compile it on his/her computer but instead of checking what's wrong with the build (whole log is in front of his/her eyes), then I'd receive message that "something is wrong", basically whenever something goes wrong you're responsible for that, which on other hand is reasonable on the other is tiring, especially when reading the message felt pretty clear Apparently not tiny amount of projcets was in "works here" state and needed some fixes that I had to do, despite not owning that code. The hint coming from it is that whenever you want to create internal tool, then remember that you'll probably be maintaining it for long time, even when you have no time allocated to do so. Also that's shocking how much maintenance can system like this actually require, damn. The gap between Old .NET and New .NET is wide, if you disliked it when using .NET Framework then I recommend giving it chance again because things are way better.4: Good/Bad Features?
Expectations rose, the building tool started being responsible for more and more things, like managing SQL files, performing static analysis using C# compiler SDK Some of those felt really weird because suggested by people who didn't use it at all and actual users said that they don't need this, but eventually I think these decisions were fine. Thus, apparently managers can be right? :)5: Thus?
I hope you can take something reasonable from this mess. I'm unable to honestly say that "that time was wasted, we could use Jenkins" or "that time was 100% well spent" from the company perspective. Is reinventing the wheel viable? That's unclear, I believe if you're big company and/or it is "core"/"important" project / part, then it makes sense. I really recommend How Tech Loses Out over at Companies, Countries and Continents, basically how do you want to have an edge over the competition if you aren't even in control of your stuff? The only thing that I can say for sure is that I "stole" a lot of experience from that project. Maybe I even abused that opportunity? tl:dr - most important things for me from this whole story- Can it be data driven? can your app perform self-configuration?
- I realized that we didn't need that significant customizability after all!
- Sane Config/Sane Defaults - you don't have to have giant XML/JSON with 10 meters of configuration, 90% of those may never be changed
- Managers can be right too :)